Estimation
An Estimation Procedure
Consider a population of N individuals, for which we wish to estimate the mean annual income,
μ. Assume that we have decided to use the following estimation procedure to make our
estimate:
- simple random sampling with replacement
- a sample size of n
- compute the sample mean, and use it as the estimate.
| Standard Notation (for simple random sampling) |
|---|
| population | sample |
| N | size | | n | size |
| μ | mean | | x | mean, estimate of μ |
| σ | standard deviation | | s | standard deviation, estimate of σ |
| X the result, viewed as a random variable |
|---|
What Can be Said about the (End Result of the) Procedure?
Remarkably, we can nail down the critical properties of X without making any assumptions at all about the nature of the distribution of individual values across the population:
| E[X] = μ |
|---|
| StdDev(X) = σ/√n |
|---|
| X is approximately normally-distributed |
|---|
The first two statements follow from elementary principles of probability: The proofs are here.
The final statement is an immediate consequence of the Central Limit Theorem, since X is computed by adding (and then dividing the result by n) a series of independent draws from the population.
Measuring Exposure to Sampling Error
How subject are we to sampling error when we use this procedure to make an estimate? We “expect” the procedure to give us the correct result. But any one time that the procedure is carried out, the actual result might differ somewhat from μ. The standard deviation of X,
called the standard error of the estimate, measures how far from μ the procedure’s result will “typically” be, and hence is a direct measure of our exposure to sampling error. We'll pull this all together into a language.
The Language of Estimation
When we make an estimate, we summarize our exposure to sampling error by using a standard
“language” to report our result. We say:
“I conducted a study to estimate {something} about {some population}. My estimate is {some
value}. The way I went about making this estimate, I had {a large chance} of ending up with an
estimate within {some small amount} of the truth.”
For example, “I conducted a study to estimate the mean gross income over the past year of
current subscribers to our biweekly magazine. My estimate is $65,230. The way I went about making
this estimate, I had a 95% chance of ending up with an estimate within $1,500 of the
truth.”
Notice how parsimonious this language is. We don’t bore the listener with unnecessary
detail concerning the data-collection procedure. Instead, we cut directly to the important issue:
How exposed to sampling error were we when we carried out the procedure? How much can our procedure
(and, perforce, the estimate we derived using it) be trusted?
The use of 95% for the "large chance" is really just a choice of dialect. Translating between dialects is simple and mechanical (as we'll see in a later example).
The "margin of error" at the 95%-confidence level follows directly from the properties of X. 95% of the time, a normally-distributed random variable (X) will take a value that differs from its expected value (μ) by no more than 1.96 standard deviations (σ/√n). Since we don't know σ, we cheat a bit and substitute s as an estimate of σ, and end up with a margin of error of 1.96 s/√n .
Estimation Terminology
the standard error of the mean (i.e., one standard-deviation's-worth of exposure to sampling error, when estimating the population mean)
|
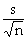 |
the margin of error of the estimate (at the 95%-confidence level) when the sample mean is used as an estimate of the population mean
|
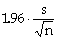 |
| a 95%-confidence interval for the population mean μ |
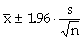 |
An Example from Advertising Sales
A magazine publishing house wishes to estimate (for purposes of advertising
sales) the average annual expenditure on furniture among its subscribers. A
sample of 100 subscribers is chosen at random from the 100,000-person
subscription list, and each sampled subscriber is questioned about his
furniture purchases in the last year. The sample mean response is $530,
with a sample standard deviation of $180.
What estimate (of the population average) should be reported?
Answer: $530.00 ± $35.28
In words: The way we made this estimate ($530) of the mean annual spending per subscriber across the entire population, we had a 95% chance of ending up with an estimate which differed from the true mean by no more than $35.28.
This example is continued on the "advertising sales" tab of this workbook. Two technical issues are dealt with there, and summarized here. The conclusion:
For estimates made using simple random sampling (with or without replacement), as long as either (a) we have a couple of dozen observations or more, or (b) we have an even smaller sample and we are willing to assert that the overall population distribution is roughly normal, then a 95%-confidence interval for the true mean is
x ± (~2)·s/√n ,
where the "~2" comes from the t-distribution with (n-1) degrees of freedom, and is typically provided to us by statistical software.
Extending the Example
We can afford to standardize our language of "trust" around the notion of 95%-confidence, because translations to other levels of confidence are simple. The following statements are totally synonymous:
I'm 90%-confident that my estimate is wrong by no more than $29.61. (~1.65)·s/√n
I'm 95%-confident that my estimate is wrong by no more than $35.28. (~2)·s/√n
I'm 99%-confident that my estimate is wrong by no more than $46.36. (~2.6)·s/√n
Optional Supplementary Material
This workbook provides a graphical illustration of the idea underlying a 95%-confidence interval.
Those seeking a more detailed discussion of the notion of "degrees of freedom" should look here.
Finally, for those familiar with the use of computer simulation for risk analysis, here's an example of how our language of "trust" comes into play in a simulation exploring the decision to enter a reseach-and-development race.